22.1.4.3数学考虑¶
已经尝试使稀疏矩阵以与完全对应矩阵完全相同的方式表现。然而,也有一些不同之处,尤其是与其他产品稀疏实现的不同之处。
首先"./"和".^"运算符必须小心使用。考虑一下这些例子
s = speye (4); a1 = s .^ 2; a2 = s .^ s; a3 = s .^ -2; a4 = s ./ 2; a5 = 2 ./ s; a6 = s ./ s;
将给予。的第一个示例s被提升到2的幂导致没有问题。然而s就其本身而言,升高的元素涉及大量的术语0 .^ 0即1。那里s.^s是一个完整的矩阵。
同样地s2.涉及以下术语0 .^ -2哪个是无穷大,所以s2.同样是一个满秩矩阵。
对于“./”运算符s2.没有问题,但是2^s也涉及大量的无穷大项,并且同样是一个满秩矩阵s./ s涉及以下术语0 ./ 0哪个是NaN所以这同样是一个零元素的满秩矩阵s充满NaN价值观
上述行为与满秩矩阵一致,但与其他产品中的稀疏实现不一致。
稀疏矩阵的一个特殊问题是从于零没有被存储,这些零的符号位也同样没有被存储。在某些情况下,零的符号位是重要的。例如
a = 0 ./ [-1, 1; 1, -1];
b = 1 ./ a
⇒ -Inf Inf
Inf -Inf
c = 1 ./ sparse (a)
⇒ Inf Inf
Inf Inf
要纠正这种行为,就意味着需要将符号位为负的零元素存储在矩阵中,以确保它们的符号位得到检视。从于效率的原因,目前还没有这样做,因此警告用户,在符号位为零很重要的情况下,不能使用稀疏矩阵进行计算。
一般来说,在稀疏矩阵上使用的任何函数或运算符都会导致稀疏矩阵的非零元素数量与原始矩阵相同或更多。这对于稀疏矩阵因子分解的重要情况尤其如此。通常的处理方法是对矩阵进行重新排序,使其因子分解比原始矩阵的因子分解更具解析性L * U = P * S * Q具有更稀疏的项L和U比等价因子分解L * U = S.
根据要分解的矩阵的类型,有几个函数可用于重新排序。如果矩阵是对称正定的,那么symamd或csymmd应该使用。否则amd, colamd或ccolamd应该使用。对于完整性,重新排序函数冷烫和随机排列也可用。
详见图22.3,是一个简单正定矩阵结构体的例子。
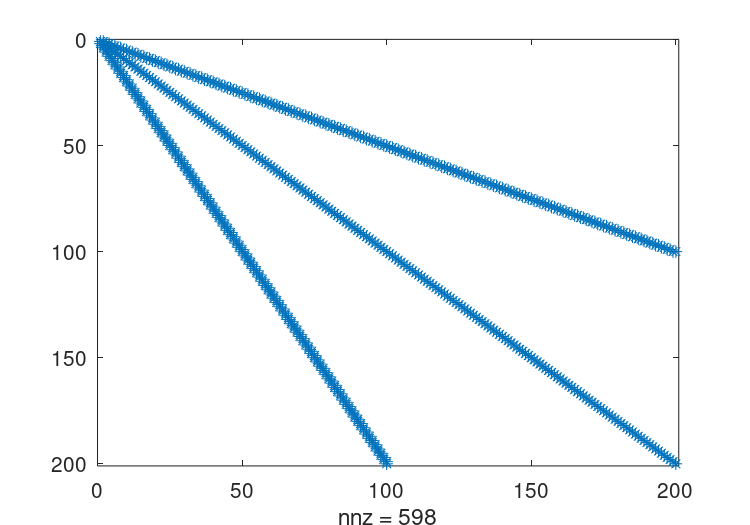
图22.3:简单稀疏矩阵的结构体。
这个矩阵的标准Cholesky因子分解可以通过与满秩矩阵相同的命令获得r = chol (A); spy (r);详见图22.4原始矩阵有598个非零项,而这种Cholesky因子分解有10200个,只存储了对称矩阵的一半。这是一个重要的填充级别,虽然对于这样一个小的测试用例来说不是问题,但它可以代表与其他稀疏矩阵一起工作的大量开销。
原始矩阵的适当的保稀疏排列从下式给出symamd并且可以使用命令来可视化使用这种重新排序的因子分解q = symamd (A);
r = chol (A(q,q)); spy (r)这给出了399个非零项,这是一个显著的改进。
Cholesky因子分解本身可以用于确定在因子分解过程中矩阵的适当的稀疏性保持重排序。在这种情况下,这可以通过三个返回参数获得[r, p, q] = chol (A); spy (r).
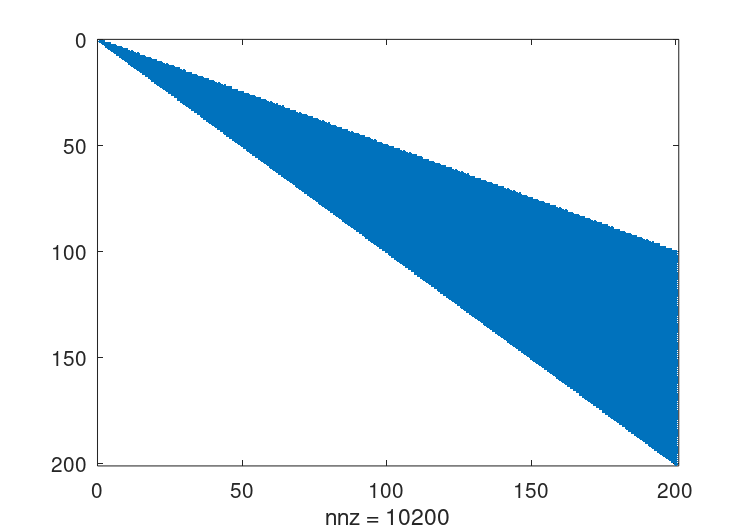
图22.4:上述矩阵的非静音Cholesky因子分解的结构体。
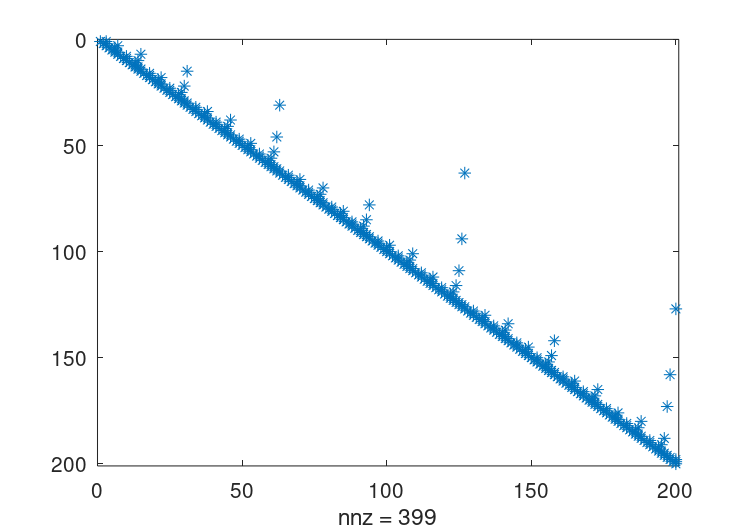
图22.5:上述矩阵的置换Cholesky因子分解的结构体。
在非对称矩阵的情况下,适当的保稀疏排列是colamd使用这种重新排序的因子分解可以使用命令进行可视化q = colamd (A); [l, u, p] = lu (A(:,q)); spy (l+u).
最后,当使用div(/)和ldiv(\)运算符时,Octave隐式地重新排序矩阵,因此用户不需要显式地重新排列矩阵以最大限度地提高性能。
- :
p =amd(S)¶ - :
p =amd(S, opts)¶ -
返回矩阵的近似最小阶置换。
这是一个置换,使得的Cholesky因子分解
S(p, p)往往比的Holesky因子分解更稀疏S它本身amd通常比symamd但具有类似的目的。可选参数opts是一个控制行为的结构体
amd。该结构体的字段为- opts稠密的
-
确定什么
amd认为是输入矩阵的密集行或列。超过的行或列最大(16,(密度*sqrt(n)))条目,其中n是矩阵的顺序S,被忽略amd在排列的计算期间。稠密的值必须是正标量,默认值为10.0 - opts侵略性的
如果该值是非零标量,则
amd进行攻击性吸收。默认情况是不进行积极吸收。
代码本身的作者是Timothy A.Davis(详见http://faculty.cse.tamu.edu/davis/suitesparse.html).
- :
p =ccolamd(S)¶ - :
p =ccolamd(S, knobs)¶ - :
p =ccolamd(S, knobs, cmember)¶ - :
[p, stats] =ccolamd(…)¶ -
约束列近似最小度置换。
p=ccolamd(S)返回稀疏矩阵的列近似最小阶置换向量S.对于非对称矩阵S,S(:, p)LU因子往往比S.chol(S(:, p)' * S(:, p))也倾向于比chol(S * S).p=ccolamd(S1.优化的排序lu(S(:, p))。排序之后是列消除树后排序。knobs是可选的1元素到5元素输入向量,默认值为
[0 10 10 1 0]如果不存在或为空。不存在的条目设置为默认值。knobs1.-
如果非零,则优化排序
lu (S(:, p))。这将是apoor顺序chol(S(:, p)' * S(:, p))。这是ccolamd最重要的旋钮。 knobs2.-
如果S是m-by-n,行数超过
max(16,knobs(2) *sqrt(n))条目被忽略。 knobs3.-
包含个以上的列
max(16,knobs(3) *sqrt(最小值(m, n)))条目被忽略,并在输出排列中最后排序(受cmember约束)。 knobs4.-
如果非零,则执行积极吸收。
knobs5.-
如果非零,则打印统计信息和旋钮。
cmember是可选的长度向量n。它定义了对列排序的约束。如果
cmemberjc,然后列j在约束集中c(c必须在1到n的范围内)。在输出排列中p,集合1中的所有列首先出现,然后是集合2中的所有列,依此类推。cmember=个(1,n)如果不存在或为空。ccolamd(S,[],1:n)退货1 : np=ccolamd(S)大约与p=colamd(S). knobs及其默认值differ。colamd它总是进行积极的吸收,并且它查找anordering适合两者lu(S(:, p))和chol(S(:, p)' * S(:, p)); 它无法优化其排序lu(S(:, p))在某种程度上ccolamd(S1.可以stats是一个可选的20元素输出向量,提供有关输入矩阵的排序和有效性的数据S。订单统计数据位于
stats(1 : 3).stats1.和stats2.是密集或空的行和列的数量,从CCOLAMD和stats3.是对使用的内部数据结构执行的垃圾收集次数CCOLAMD(大致大小2^2*nnz(S4.m7.n整数)。stats(4 : 7)如果CCOLAMD能够继续提供信息。如果stats4.为零,如果无效则为1。stats5.是最右边的列索引,该列已被检测或包含重复条目,如果不存在此类列,则为零。stats6.是给定的列索引中最后一个出现重复或无序的行索引stats5.,如果不存在这样的行索引,则为零。stats7.是重复或无序行索引的数量。stats(8 : 20)在当前版本中始终为零CCOLAMD(保留以备将来使用)。代码本身的作者是S.Larimore、T.Davis和S。Rajamanickam与J.Bilbert和E.Ng合作。从国家科学基金会(DMS-9504974、DMS-9803599、CCR-0203270)和桑迪亚国家实验室资助。见http://faculty.cse.tamu.edu/davis/suitesparse.html用于ccolamd、csymmd、amd、colamd、symamd和其他相关订单。
- :
p =colamd(S)¶ - :
p =colamd(S, knobs)¶ - :
[p, stats] =colamd(S)¶ - :
[p, stats] =colamd(S, knobs)¶ -
计算列的近似最小度排列。
p=colamd(S)返回稀疏矩阵的列近似最小阶置换向量S.对于非对称矩阵S,S(:,p)LU因子往往比S的Cholesky因子分解S(:,p)' * S(:,p)也往往比的稀疏S * S.knobs是一个可选的一到三元素输入向量。如果S是m-by-n,则具有多个的行
max(16,knobs(1) *sqrt(n))条目被忽略。超过的列max(16,knobs(2) *sqrt(最小值(m,n))条目在排序之前被删除,并在输出排列中最后排序p。如果knobs1.和knobs2.分别<0。如果knobs3.不是零,stats和knobs打印。默认为knobs= [10 10 0]。请注意knobs与早期版本的colamd不同。stats是一个可选的20元素输出向量,提供有关输入矩阵的排序和有效性的数据S。订单统计数据位于
stats(1:3).stats1.和stats2.是密集或空的行和列的数量,从COLAMD和stats3.是对使用的内部数据结构执行的垃圾收集次数COLAMD(大致大小2^2*nnz(S4.m7.n整数)。Octave内置函数用于生成有效的稀疏矩阵,其中没有重复的条目,每列的行索引为非零,每列中的条目数为非负数(!),依此类推。如果矩阵无效,则COLAMD可能能够继续,也可能无法继续。如果存在重复条目(一个行索引在同一列中出现两次或多次),或者一列中的行索引无序,则COLAMD可以通过忽略重复条目并对矩阵内部副本的每列进行排序来更正这些错误S(输入矩阵S但是未修复)。如果amatrix在其他方面无效,那么COLAMD无法继续,打印错误消息,并且没有输出参数(p或stats)返回。COLAMD因此是检查稀疏矩阵是否有效的一种简单方法。
stats(4:7)提供信息,如果COLAMD能够继续。如果stats4.为零,如果无效则为1。stats5.是最右边的列索引,该列已被检测或包含重复条目,如果不存在此类列,则为零。stats6.是给定的列索引中最后一个出现重复或无序的行索引stats5.,如果不存在这样的行索引,则为零。stats7.是重复或无序行索引的数量。stats(8:20)在当前版本中始终为零COLAMD(保留以备将来使用)。排序之后是列消除树后排序。
代码本身的作者是Stefan I.Larimore和Timothy A.Davis。该算法是与施乐PARC的John Gilbert和橡树岭国家实验室的Esmond Ng合作开发的。详见http://faculty.cse.tamu.edu/davis/suitesparse.html)
- :
p =colperm(s)¶ -
返回列排列,以便的列
s(:, p)按照非零元素数量的增加进行排序。如果s是对称的,那么p是这样选择的
s(p, p)在非零元素数量不断增加的情况下对行和列进行排序。
- :
p =csymamd(S)¶ - :
p =csymamd(S, knobs)¶ - :
p =csymamd(S, knobs, cmember)¶ - :
[p, stats] =csymamd(…)¶ -
对于对称正定矩阵S,返回排列向量p使得
S(p,p)倾向于具有天冬氨酸Cholesky因子S.有时
csymamd也适用于对称不定矩阵。矩阵S被假定为对称的;只有严格意义上的下三角部分被引用。S必须是方形的。排序之后是一个消除树后排序。knobs是可选的1元素到3元素输入向量,默认值为
[10 1 0]。不存在的条目设置为默认值。knobs1.-
如果S是n-by-n,则具有多个的行和列
max(16,knobs(1) *sqrt(n))条目被忽略,并在输出排列中排序为最后一个(受cmember约束)。 knobs2.-
如果非零,则执行积极吸收。
knobs3.-
如果非零,则打印统计信息和旋钮。
cmember是长度为n的可选向量。它定义了排序的约束。如果
cmemberjS,则行/列j为约束集c(c必须在1到n的范围内)。在输出排列中p,集合1中的行/列首先出现,然后是集合2中的所有行/列,依此类推。cmember=个(1,n)如果不存在或为空。csymmd(S,[],1:n)退货1:n.p=csymmd(S)大约与p=符号(S). knobs及其默认值differ。stats(4:7)如果CCOLAMD能够继续提供信息。如果stats4.为零,如果无效则为1。stats5.是最右边的列索引,该列已被检测或包含重复条目,如果不存在此类列,则为零。stats6.是给定的列索引中最后一个出现重复或无序的行索引stats5.,如果不存在这样的行索引,则为零。stats7.是重复或无序行索引的数量。stats(8:20)在当前版本中始终为零CCOLAMD(保留以备将来使用)。代码本身的作者是S.Larimore、T.Davis和S。Rajamanickam与J.Bilbert和E.Ng合作。从国家科学基金会(DMS-9504974、DMS-9803599、CCR-0203270)和桑迪亚国家实验室资助。见http://faculty.cse.tamu.edu/davis/suitesparse.html用于ccolamd、colamd、csymmd、amd、colamd、symamd和其他相关订单。
- :
p =dmperm(A)¶ - :
[p, q, r, s, cc, rr] =dmperm(A)¶ -
执行稀疏矩阵的Dulmage-Mentelsohn置换A.
带有单个输出参数
dmperm,返回最大匹配p使得p(j) = iif列j与行匹配i,或0 ifcolumnj是无与伦比的。如果A是正方形和全结构体等级,p是一个行排列,并且A(p,:)具有零自从对角线。的结构体级别A是sprank(A) = sum(p>0).使用两个或多个输出参数调用,返回的Dumage Mendelsohn分解A. p和q是置换向量。cc和rr是长度为5的向量。
c = A(p,q)被分割成一组4乘4的粗略块:A11 A12 A13 A14 0 0 A23 A24 0 0 0 A34 0 0 0 A44这里的
A12,A23和A34是零自从对角线的正方形。的列A11是不匹配的列和行A44是不匹配的行。这些块中的任何一个都可以为空。在“粗略”分解中,第(i,j)个块是C(rr(i):rr(i+1)-1,cc(j):cc(j+1)-1)就线性系统而言,[A11 A12]是系统的欠定部分(它总是矩形的,具有更多的列和行,或0乘0),A23是系统的决定性部分(它总是方形的),以及[A34 ; A44]是系统的过度确定部分(它总是矩形的,行多于列,或者0乘0)。的结构体级别A是
sprank (A) = rr(4)-1,它是的数值秩的上界A.sprank(A) = rank(full(sprand(A)))精确算法中的概率为1。这个
A23子矩阵通过“精细”分解(的强连通分量A23).如果A是正方形的并且在结构体上是非奇异的,A23是整个矩阵。C(r(i):r(i+1)-1,s(j):s(j+1)-1)是精细分解的第(i,j)个块。(1,1)块是矩形块[A11 A12],除非此块是0乘0。(b,b)块是矩形块[A34 ; A44],除非此块为0乘0,其中b = length(r)-1.表单的所有其他块C(r(i):r(i+1)-1,s(i):s(i+1)-1)是的对角块A23,和是具有零自从对角线的正方形。所使用的方法描述于:A.Pothen&C.-J.Fan。稀疏矩阵的块三角形式的计算.ACM Trans。数学软件,16(4):303-3241990。
- :
p =symamd(S)¶ - :
p =symamd(S, knobs)¶ - :
[p, stats] =symamd(S)¶ - :
[p, stats] =symamd(S, knobs)¶ -
对于对称正定矩阵S,返回排列向量p,使得
S(p, p)倾向于具有天冬氨酸Cholesky因子S.有时
symamd也适用于对称不定矩阵。矩阵S被假定为对称的;只有严格意义上的下三角部分被引用。S必须是方形的。knobs是一个可选的一到二元素输入向量。如果Sisn-by-n,然后是具有多个的行和列
max(16,knobs(1) *sqrt(n))条目在排序之前被删除,并在输出排列中最后排序p.如果knobs(1) < 0如果knobs2.为非零,stats和knobs打印。默认为knobs= [10 0]。请注意knobs与的早期版本不同symamd.stats是一个可选的20元素输出向量,提供有关输入矩阵的排序和有效性的数据S。订单统计数据位于
stats(1:3).stats1.stats2.是SYMMAMD忽略的密集或空行和列的数量,以及stats3.是对SYMMAMD使用的内部数据结构执行的图像收集的数量(大致为8.4*nnz(颤音(S, -1)) + 9 * n整数)。Octave内置函数用于生成有效的稀疏矩阵,其中没有重复条目,每列的行索引为非零,每列中的条目数为非负数(!),依此类推。如果矩阵无效,则SYMMAMD可能无法继续。如果存在重复条目(一个行索引在同一列中出现两次或多次),或者一列中的行索引出现故障,则SYMMAMD可以通过忽略重复条目并对矩阵S的内部副本的每列进行排序来纠正这些错误(然而,输入矩阵S不会被修复)。如果矩阵在其他方面无效,则SYMMAMD无法继续,将打印错误消息,并且没有输出参数(p或stats)返回。SYMMAMD是一种检查稀疏矩阵是否有效的简单方法。
stats(4:7)如果SYMMAMD能够继续提供信息。如果stats4.为零,或者1如果无效。stats5.是未排序或包含重复项的最右侧列索引,如果不存在此类列,则为零。stats6.是给定的列索引中最后一个出现重复或无序的行索引stats5.,如果不存在此类行索引,则为零。stats7.是重复或无序行索引的数量。stats(8:20)在SYMMAMD的当前版本中始终为零(保留以供将来使用)。排序之后是列消除树后排序。
代码本身的作者是Stefan I.Larimore和Timothy A.Davis。该算法是与施乐PARC的John Gilbert和橡树岭国家实验室的Esmond Ng合作开发的。详见http://faculty.cse.tamu.edu/davis/suitesparse.html)
- :
p =symrcm(S)¶ -
返回的对称逆Cuthill-MMcKee置换S.
p是一个置换向量,使得
S(p, p)其对角线元素往往比S这是来自“长,瘦”问题的矩阵的LU或Cholesky因子分解的一个很好的预序。它适用于对称和非对称S.该算法代表了NP完全带宽最小化问题的一种启发式方法。实现基于中的描述
E.Cuthill,J.McKee。减少稀疏对称矩阵的带宽.第24届美国计算机学会全国会议论文集,157-1721969,布兰登出版社,新泽西州。
A.乔治,J.W.H.刘。大稀疏正定系统的计算机解法,Prentice Hall计算数学系列,ISBN 0-13-165274-51981。